Physics ex Machina
The following was originally posted on the Lindau Nobel Laureate Meeting blog here.
For the most part, physics is taught with the pen and paper approach to solving problems in mind. Be it through a lengthy derivation during a lecture or a particularly tricky exam question, the only problems worth solving appear to be those that are tractable and neat, at least early on in the physics curriculum. This generalisation is dissipating with time and most undergraduate physics courses have begun incorporating more and more data collection and analysis in their hands-on labs, though not much is typically expected from these early forays into data handling beyond the manipulation of a few pre-prepared spreadsheets. Moving to the ‘real world’ that is physics research, physics subdisciplines and research areas find themselves requiring the help of complicated computational techniques to handle the complexity and volume of data that is encountered in their individual quests for knowledge.
It is clear now, more than ever, that proficiency with computers, programming, and computer science is extremely important for most physicists no matter their interests. In this short post I will focus on but one small branch from the larger tree that is computer science and examine how some physicists are picking the fruits of computational research and applying it to their own projects.
Machine Learning
The particular field I’ve chosen to highlight here is that of machine learning (ML). ML is a natural point of focus as it is currently one of the hottest fields around, with nary a day going by without a multibillion dollar tech giant referring to ‘Deep Learning’, ‘Artificial Intelligence’, or ‘Big Data’ being what drives their various projects. Buzzwords aside, ML can be broadly defined as techniques that allow computers to perform tasks without being given explicit instructions by the programmer. This vagueness is extremely powerful for both experimentalists and theorists in situations where there may be no closed form method to solve a particular problem. First, we will examine an example from experimental nuclear physics and how ML greatly simplifies a time consuming and arduous task.
The Experimental Case
Traditionally, many experiments in my particular field (low-energy nuclear physics) have relied on rather simple and brute-force techniques when it comes to data analysis. Data will be collected over the course of a several weeks long beamtime and then be examined by hand (with some preprocessing) to determine the outcome. For the history of the field this has been adequate and has allowed for some truly incredible discoveries. However, accelerators that are slated to come online in the next few years (e.g. FRIB) will produce much more data than previous experiments without a proportionate number of graduate students to analyse the data. Indeed, this problem of ‘too much data’ is one that has been encountered by many other fields and experimental endeavours like the Large Hadron Collider (LHC) at CERN which uses ML in a combination of online measurements to decide whether to take data or not and post-collection analysis to make understanding the data feasible.
As one example, Michelle Kuchera from Davidson College has pulled from other fields of physics and recent research in the field of deep convolutional neural networks (CNN) to take nuclear reaction data from the Active Target – Time Projection Chamber (AT-TPC) at Michigan State University and classify this data into specific categories of events. This is an excellent example of what is called a classification problem and uses state of the art computational techniques in an attempt to remove a bottleneck from her research. Essentially, these CNNs are trained with images that have an assigned label and then are tested with new images that it has not seen before. This is the same technique that image recognition software uses to determine whether there is a face (and whose face it is) in a photo or video. It turns out that a lot of what is required in the data analysis process is simply recognising certain classes of events from an ‘image’ or experimental output in this case, and thus can bypass the human element to allow for the processing of vastly enlarged data sets. Next, we shall consider another tricky issue by way of a toy model in my home field of nuclear theory.
Speaking Theoretically
Rather than examining an actual use case, I’ll present a toy model that uses a simple artificial neural network (ANN) and gets at what makes ML so powerful in some instances. For this example, consider the binding energy per nucleon of various nuclei. This quantity is often used as a test of nuclear mass models and there is ample experimental data to compare with. In contrast to a classic model like the liquid drop model (LDM) which assumes a particular form of neutron and proton dependence, I’ve constructed a very simple ANN which takes only proton (Z) and neutron (N) numbers as inputs and outputs a binding energy. The way the network comes to learn what binding energies should correspond to a given N and Z is by training the ANN to experimental data (the Ame2016 mass evaluation was used in this case). However, to avoid over-fitting, one breaks off a chunk from the full data set called the ‘test set’ which is set aside and only used at the end to check how well the network performs. This use case of an ANN is an example of a regression ML problem, which amounts to a fancy form of curve fitting. In the following figure I plot the output of the ANN for N and Z values that it was not trained on (the test set) on top of the full experimental data set:
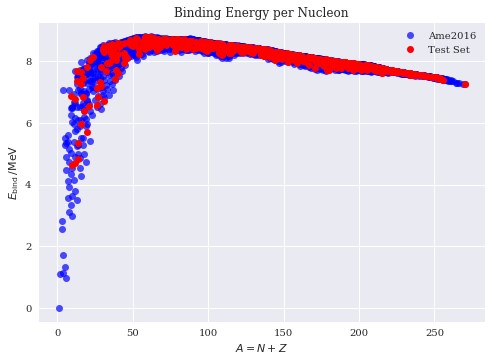
The preceding network was built using a few lines of Python code using Google’s TensorFlow library which provides an extremely powerful yet accessible framework for non-experts to experiment with ML.
It should be reiterated that the structure of the ANN was completely arbitrary and general and no assumptions were made regarding what the output ‘should’ be and yet our test data falls nicely within the experimental data bounds. A hurdle that physicists must overcome when attempting to apply ML techniques to their own research is to embrace the arbitrariness, as we scientists will often try to include more information than is needed when designing the input and output data for an ANN. Including too much ‘physics’ can sometimes bias the network in a negative way and harm generality.
Final Thoughts
By applying supervised learning ML techniques to various problems in physics, it is clear that ML offers a powerful set of tools to perform ill-defined or intractable tasks in both experimental and theoretical settings. While some of our colleagues have been using these specific tools for quite a while, we often learn of the existence of ML far too late in our careers. This is true of many other basic and advanced computational fields as well, which is a sign that physics education may be missing a critical learning opportunity when designing curricula. Ideally, physics departments would work closely with computer science departments to ensure their students were well versed in the technical skills and computational theory that may be useful, though even a basic programming overview in an introductory lab would be preferred to pretending that computational skills aren’t going to be necessary down the road. Indeed, close collaboration between computer science and physics has already led to some previously impossible feats, imagine what could be achieved if these skills were implanted at the beginning of our journeys through physics.
Kyle Godbey
Research Assistant Professor
I use computational techniques to study a wide range of nuclear and nuclear-adjacent physics.